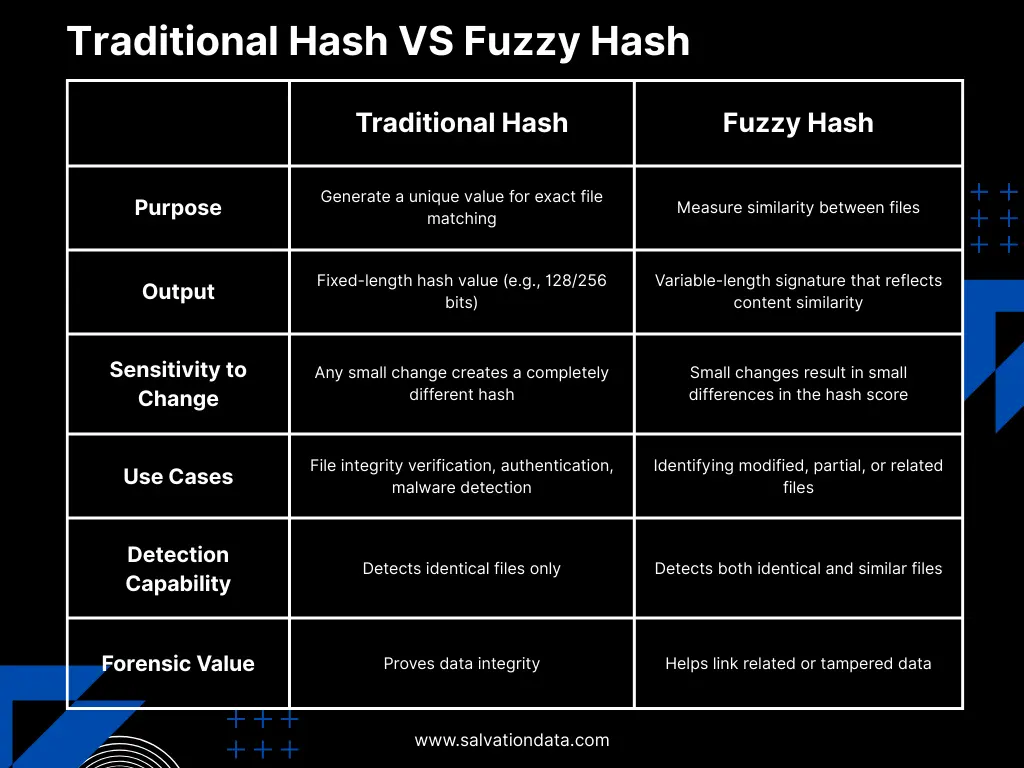
Hash functions are one of the cornerstones of modern computing. They transform data into fixed-length strings of characters, making it easy to verify integrity, secure information through encryption, and ensure consistency in digital forensics. Investigators and cybersecurity experts rely on cryptographic hashes like MD5 or SHA-1 to confirm whether a file has been altered—even the smallest change produces a completely different hash value.
But here’s the challenge: in real-world investigations, files are rarely identical. Malware samples often appear in multiple slightly modified versions, and digital evidence may be fragmented or partially corrupted. In these scenarios, traditional hashing falls short because it only works with exact matches.
This is where the question arises: what is fuzzy hashing, and why do we need it? Unlike conventional hashing methods that demand perfect equality, fuzzy hashing provides a way to detect similarities between data. It fills the critical gap when investigators need to identify files that are not exactly the same but still closely related—a capability that has become indispensable in modern digital forensics and cybersecurity.